Vertical K-means
Introduction
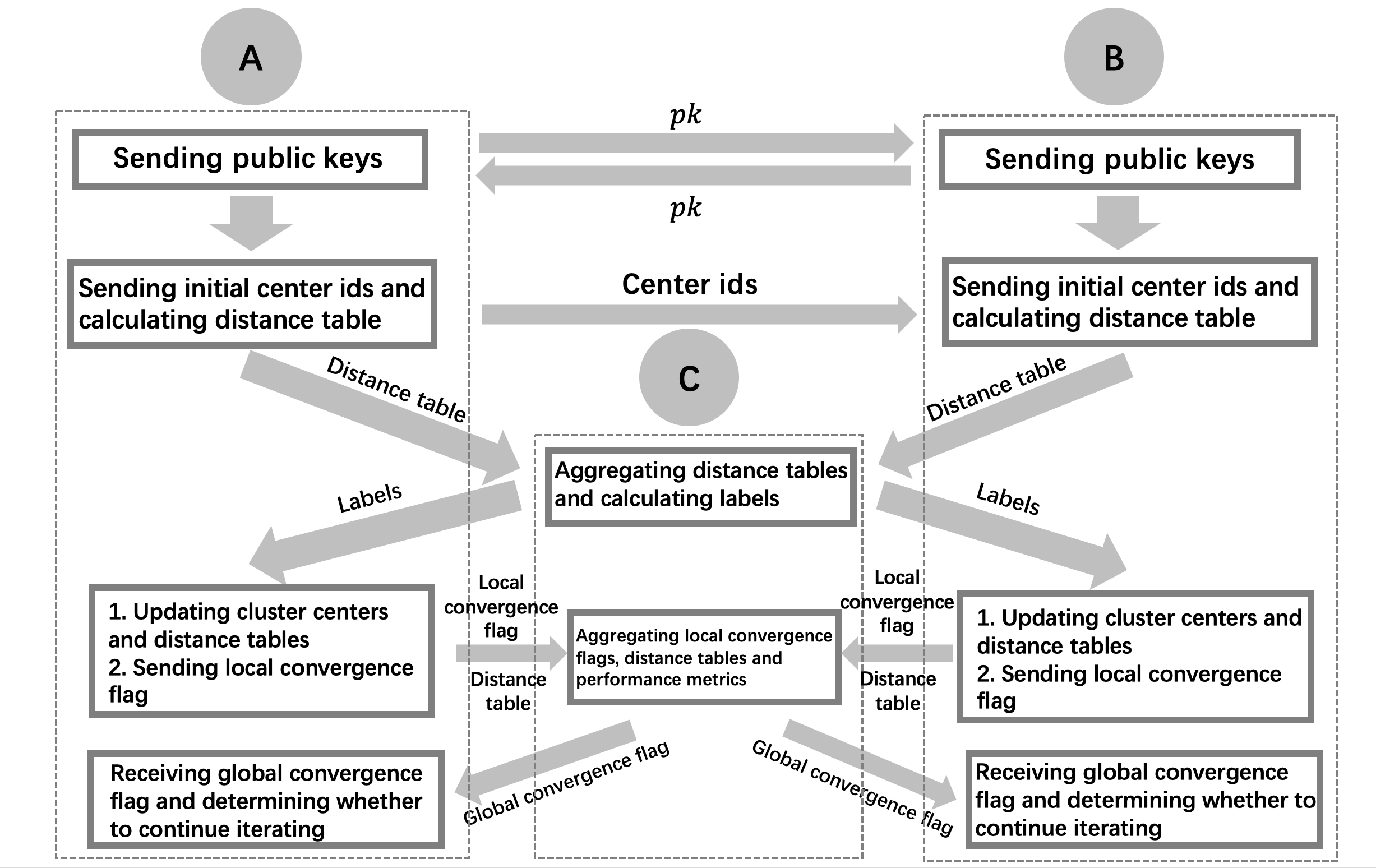
The calculation process for vertical Kmeans (two parties in this example) is illustracted as follows, where A and B are the trainer and the label_trainer who own the data, C is the assist_trainer who performs aggregation operations.
Parameters List
identity: str The role of each participant in federated learning, should be one of label_trainer, trainer or assist trainer.
- model_info:
name:
strModel name, should be vertical_kmeans.
- input:
- trainset:
type:
strTrain dataset type, currently supported is csv.path:
strThe folder path of train dataset.name:
strThe file name of train dataset.has_id:
boolWhether the dataset has id column.has_label:
boolWhether the dataset has label column.
- output:
path:
strOutput folder path.- model:
name:
strFile name of output model.
- result:
name:
strFile name of result.
- summary:
name:
strFile name of summary.
- train_info:
- train_params:
init:
strInitialization method, should be one of random and kmeans++.- encryption:
- otp:
key_bitlength:
intKey length of one time pad encryption, support 64 and 128.data_type:
strInput data type, support torch.Tensor and numpy.ndarray, depending on model data type.- key_exchange:
key_bitlength:
intBit length of the key, recommend to be greater than or equal to 2048.optimized:
boolWhether to use optimized method.
- csprng:
name:
strPseudo-random number generation method.method:
strCorresponding hash method.
k:
intNumber of clusters.max_iter:
intMaximum iteration.tol:
floatConvergence threshold.random_seed:
intRandom seed.