Vertical XGBoost
Introduction
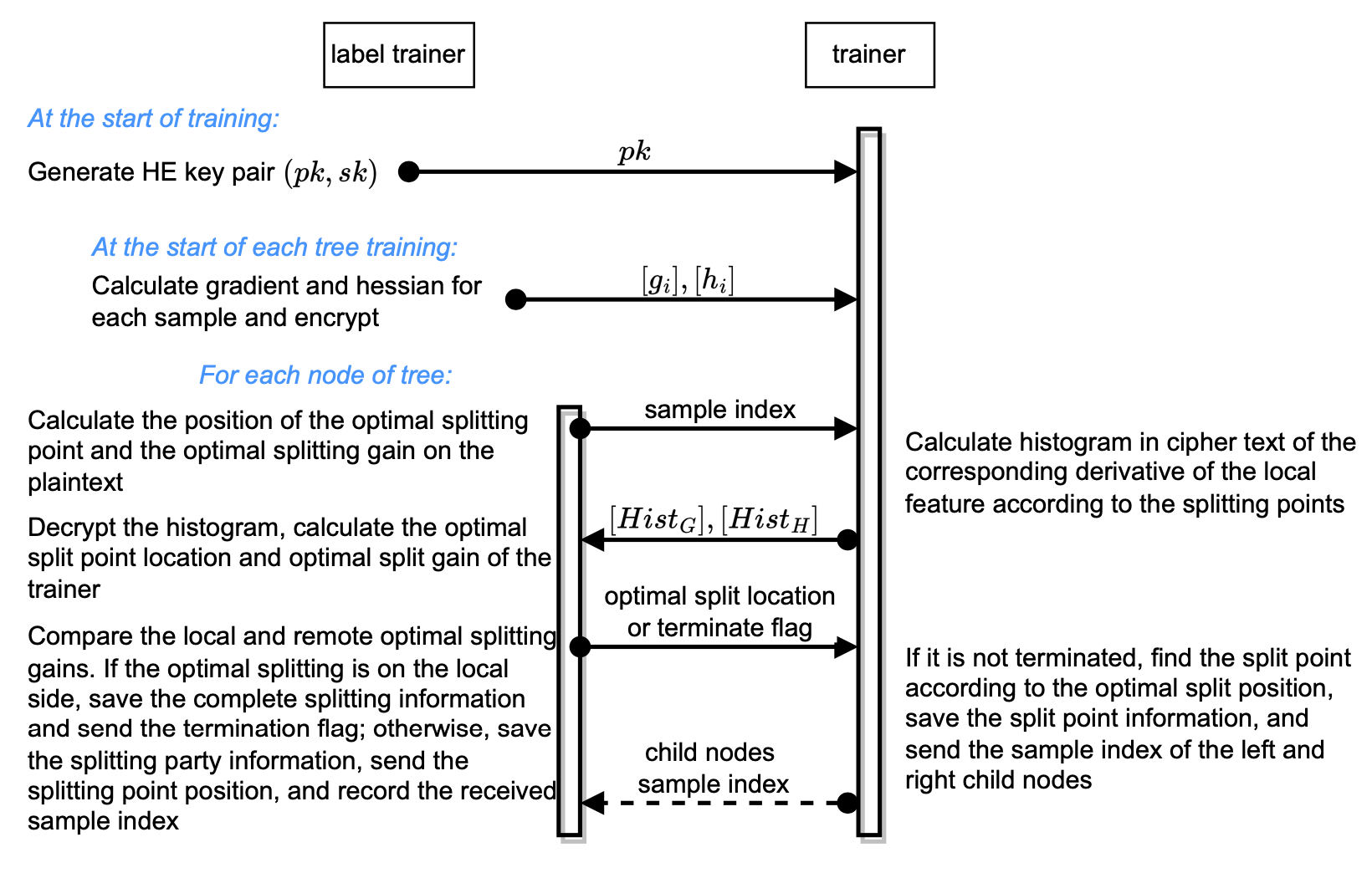
The vertical XGBoost is a federated implementation of the popular machine learning model XGBoost. The label trainer receives the sum of the first and second order derivatives split by bins from the trainer, ensuring no leakage on the feature values of trainer as well as their comparative relationship. On the other side, the trainer get the homomorphic ciphertext of the first and second order derivatives, ensuring no leakage on the label and features of the label trainer, as well as the derivatives.
The algorithm can be described as follows:
Parameters List
identity: str Federated identity of the party, should be one of label_trainer, trainer or assist trainer.
- model_info:
name:
strModel name, should be vertical_xgboost.
- input:
- trainset:
type:
strTrain dataset type, support csv.path:
strIf type is csv, folder path of train dataset.name:
strIf type is csv, file name of train dataset.has_id:
boolIf type is csv, whether dataset has id column.has_label:
boolIf type is csv, whether dataset has label column.
- valset:
type:
strValidation dataset type, support csv.path:
strIf type is csv, folder path of validation dataset.name:
strIf type is csv, file name of validation dataset.has_id:
boolIf type is csv, whether dataset has id column.has_label:
boolIf type is csv, whether dataset has label column.
- output:
path:
strFolder path of output.- model:
name:
strFile name of output model.
- metric_train:
name:
strFile name of trainset metrics.
- metric_val:
name:
strFile name of valset metrics.
- prediction_train:
name:
strFile name of trainset prediction.
- prediction_val:
name:
strFile name of valset prediction.
- ks_plot_train:
name:
strFile name of trainset ks values.
- ks_plot_val:
name:
strFile name of valset ks values.
- decision_table_train:
name:
strFile name of trainset decision table.
- decision_table_val:
name:
strFile name of valset decision table.
- feature_importance:
name:
strFile name of feature importance table.
- train_info:
- interaction_params:
save_frequency:
intFrequency(per tree) to save model, set to -1 for not saving model.echo_training_metrics:
boolWhether to output metrics on train dataset.write_training_prediction:
boolWhether to save predictions on training dataset.write_validation_prediction:
boolWhether to save predictions on validation dataset.
- train_params:
lossfunc:
mapConfiguration of loss function. Key is the loss name, value is its parameters. For example. “BCEWithLogitsLoss”: {}num_trees:
intNumber of trees.learning_rate:
floatLearning rate.gamma:
floatL1 regularization term on number of leafs.lambda:
floatL2 regularization term on weights.max_depth:
intMax depth of tree.num_bins:
intMax number of bins.min_split_gain:
floatMin split gain.min_sample_split:
intMin number of samples in a tree node.feature_importance_type:
strType of feature importance, support gain and split.- downsampling:
map - column:
map rate:
floatSubsample rate of feature dimension.
- column:
- row:
map run_goss:
boolWhether to use goss sampling.top_rate:
floatThe retain ratio of large gradient data in goss.other_rate:
floatThe retain ratio of small gradient data in goss, 0 < top_rate + other_rate <= 1.
- row:
- downsampling:
- category:
map cat_smooth:
floatUsed for reducing the effect of noises in categorical features. Default to 0.- cat_feature:
mapFor defining which columns are categorical feature columns. The formulation is: features that column indexes are in col_index if col_index_type is ‘inclusive’ or not in col_index if col_index_type is ‘exclusive’. union` featuresthat column names are in col_names if col_names_type is ‘inclusive’ or not in col_names if col_names_type is ‘exclusive’. union if max_num_value_type is ‘union’ or intersect if max_num_value_type is ‘intersection’ features that number of different values is less equal than max_num_value. col_index
str: Column index of features which are supposed to be (or not to be) a categorial feature. Accept slice or number, for example: “1, 4:5”. Defaults to “”.col_names
list<str>: Column names of features which are supposed to be (or not to be) a categorical feature. Defaults to [].max_num_value
int: If n <= max_num_value where n is the number of different values in a feature column, then the feature is supposed to be a category feature. Defalts to 0.col_index_type
str: Support ‘inclusive’ and ‘exclusive’. Defaults to ‘inclusive’.col_names_type
str: Support ‘inclusive’ and ‘exclusive’. Defaults to ‘inclusive’.max_num_value_type
str: Support ‘intersection’ and ‘union’. Defaults to ‘union’.
- cat_feature:
- category:
- metric:
mapMetrics to output, all the keys are optional. - decision_table:
map method:
strSupport “equal_frequency” and “equal_with”bins:
intnumber of bins in decision table
- decision_table:
acc: {}
precision: {}
recall: {}
f1_score: {}
auc: {}
ks: {}
- metric:
- early_stopping:
key:
strMetrics name for early stopping.patience:
intNumber of steps with no improvement after which training will be stopped.delta:
floatMinimum change in the value of metric to qualify as an improvement.
- encryption:
- paillier:
key_bit_size:
intBit length of paillier key, recommend to be greater than or equal to 2048.precision:
intPrecison.djn_on:
boolWhether to use djn method to generate key pair.parallelize_on:
boolWhether to use multicore for computing.
plain:
mapNo encryption, an alternative to paillier encryption, please set to “plain”: {}.
max_num_cores:
intMax number of cpu cores for computing.batch_size_val:
intBatch size for validation.- advanced:
map col_batch:
intNumber of features used in a batch during node splitting.row_batch:
intNumber of samples used in a batch during node splitting.
- advanced:
- SecureBoost
Cheng K, Fan T, Jin Y, et al. Secureboost: A lossless federated learning framework[J]. IEEE Intelligent Systems, 2021, 36(6): 87-98.